Nowadays, data exists in many formats, is presented in real-time streams, and extends across multiple and various data centres and clouds all over the world. From analytics to data engineering, and AI/ML to data-driven applications; the ways in which we use and share data keep on expanding. Insights are not exclusive to analysts anymore, but now influence the actions of every employee, customer and partner. With the dramatic growth in the amount and types of data, workloads and users, we are at a tipping point where traditional data architectures – even when deployed in the cloud – are unable to unlock their full potential. As a result, the data-to-value gap is widening.
To break this pattern, a totally different approach is required. One where existing boundaries are eliminated and where traditional limits are abolished. One where different data cloud innovations allow clients to work with any data, across all and any workloads and different suppliers. One where access to different environments can be unified. One where data can be delivered real-time, and where the access to data can be democratised maximally. One where anyone with the right rights can gain necessary insights without having any data science knowledge.
That’s what the Data Cloud Summit of April was all about: a new, limitless data environment with a host of new solutions and an ever-growing ecosystem. We have collected the most important updates for you here!
Continue reading: Limitless Data. All Workloads. For Everyone
It is useful to realise here that this new step would never have been possible if Google had not laid the foundations in recent years. In the next blog, you can find an image of how Google has set up their data environment. They have focused on reliability and availability, on security and maintenance, on integration with the rest of the GCP ecosystem, on a correct pricing policy and cost transparency, and on visibility and smooth migration possibilities.
Continue reading: Google Cloud’s key investment areas to accelerate your database transformation
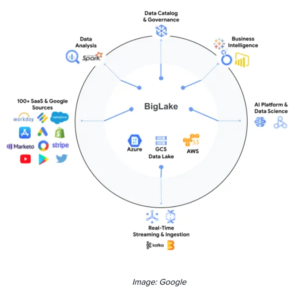
BigLake: the next big thing in the Google data landscape
The amount of analysable data that organisations have to manage and investigate, is increasing every year at an incredible speed. Furthermore, that data is spreading across various locations, among which warehouses, data lakes and NoSQL stores. As an organisation’s data is becoming more and more complex and only diffusing further, silos arise which increase the risks and costs and make the complexity of it all hard to mitigate.
What if, however, you would be able to approach your entire data environment through a unified storage engine, be it with structured or unstructured data and regardless of the data’s location (on GCP, on prem or at another public cloud player)? As a company, you would be able to generate insights much more easily without having to move data or having to take underlying storage formats into account. That is, in a nutshell, what BigLake wants to realise. It has been made available since April in preview.
In fact, Google is building on what they had already made possible for the SQL-based environment with BigQuery Omni. Nonetheless, unstructured data is also included in the story now. With BigLake, users receive intricate access control, along with performance acceleration in BigQuery, and multi cloud data lakes on AWS and Azure. That is how BigLake is making data uniformly accessible in Google Cloud and open source engines with consistent security.

BigLake enables you to:
- Expand BigQuery to multi cloud data lakes and open formats, such as Parquet and ORC, with intricate security checks and without the need to set up a new infrastructure;
- Save single copies of data, and to enforce consistent access control for analyse engines of your choosing, including Google Cloud and open source technologies, such as Spark, Presto, Trino and Tensorflow;
- Realise unified governance and maintenance at scale through seamless integration with Dataplex.
By creating BigLake tables, BigQuery clients can extend their workloads to data lakes, built on GCP, Amazon and Azure. BigLake tables are made by using a cloud resource connection, which is a service identity wrapper, making governance capabilities possible. That is how administrators can manage the access control for those tables, similar to BigQuery tables, and why it is no longer needed to grant end users access to object storage.
Data administrators can configure security on BigLake tables at both table, row and column level, by using policy tags. For BigLake tables defined on Google Cloud Storage, intricate security is consistently maintained across both Google Cloud and supported open source engines, using BigLake connectors. For BigLake tables defined on Amazon and Azure, BigQuery Omni enables managed multicloud analysis by enforcing security controls. It allows you to manage single copies of data including BigQuery and the data lakes, thus creating interoperability between data warehousing, data lakes and data science use cases.
Therefore, you can perform multiple analytical runtimes on data spread across warehouses and lakes in a controlled manner with BigLake. The solution breaks through data silos, significantly reduces infrastructure management, and associated costs, while improving your analytics stack and enabling new usage scenarios.
Continue reading: BigLake: unifying data lakes and data warehouses across clouds
Working on a broad Google data ecosystem
The Data Cloud Summit also paid quite some attention to the ecosystem Google set up around data. As we do live in a hybrid world, it is only through intensive collaboration that we, as organisations, can make the most of the available data.
By establishing the Data Cloud Alliance, which include Confluent, Databricks, Dataiku, Deloitte, Elastic, Fivetran, MongoDB, Neo4j, Redis and Starburst, Google is facilitating the open approach in their BigLake strategy. After all, that alliance aims to make the portability of data and easy access to different platforms possible by using open standards. It is a basic requirement for companies who wish to transition into digital enterprises. Google assumes digital enterprises will eventually evolve into multi cloud environments through the selection of a series of SaaS players and cloud providers. It entails that their data will always be on a series of different platforms. The players will always dispose of a variation of, for instance, analytical tooling because of specific needs or because of a history of mergers and acquisitions. We are therefore constantly evolving to heterogeneous environments where companies – if they wish to extract maximum insights from their data – need an overarching approach and intensive collaboration with different vendors. That is exactly what Google is aiming for with the alliance.
Another novelty was the Google Cloud Ready – BigQuery initiative. With this, Google wants to assign a kind of quality label to partner solutions that are being offered in combination with BigQuery. To obtain the label, Google uses a validation program in which Google Cloud engineering teams are evaluating and validating BigQuery integrations and connectors with a series of integration tests and benchmarks solutions. When launched in April, some twenty five companies had already been validated positively.
In addition, Google focused on some seven hundred technology partners on the Cloud Data Summit, who use the BigQuery Platform as the basis of their solution. For this reason, Google launched the Built with BigQuery initiative. With this action, ISVs can start building applications by using data and machine learning products, such as BigQuery, Looker, Spanner and Vertex AI. The program offers special access to Google Cloud expertise, training and co-marketing support to help partners build capacity and go to market. Moreover, Google Cloud engineering teams are working closely together with our partners on product design and optimisation, and sharing architectural patterns and best practices. That is how SaaS companies can utilise the full potential of data to stimulate innovation on a large scale.
Finally, Google also put a fair amount of new products and partners in the spotlight on the event. The summit announced Databricks, Fivetran, MongoDB, Neo4j and Starburst Data, to name a few.
Continue reading: Investing in our data cloud partner ecosystem to accelerate data-driven transformations
Also read: Over 700 tech companies power their applications using Google’s data cloud
Vertex AI continues to lower the threshold for widespread use of AI. Without the right up-to-date data, you risk having outdated, sub-optimal models. Without AI, you’ll never get the most out of your data..
In previous editions, we have written about the fact that many companies are experimenting with AI, but also that most companies find it challenging to deliver usable and durable AI solutions in a real production environment. That is why Google has provided for AutoML functions and Vertex AI tools in recent years, to make the AI story really take hold in the field.
On the Data Summit of April, a few new elements were added to the list:
- The Vertex AI Workbench is now officially and generally available. With this product, Google brings the data and ML systems of Google Cloud together in one single interface, so teams have a common toolset to their disposal for data analysis, data science and machine learning. With native integrations in BigQuery, Spark, Dataproc and Dataplex, data scientists can build, train and implement ML models five times as fast as traditional notebooks;
- By introducing Vertex AI Model Registry, Google is now offering a central repository to set up and manage the lifecycle of ML models. Designed to work with every type of model and implementation goal, including BigQuery ML, Vertex AI Model Registry is simplifying the management and implementation of models.
Continue reading: Meet Google’s unified data and AI offering
Spanner data more easily selectively available for analysis
More and more companies are data-driven, and data has become their most valuable asset. One way to unlock the value of that data is by giving it a life of its own. For example, a transactional database, such as Cloud Spanner, captures incremental changes to your data in real-time and at scale, so you can start using them in more powerful ways. The traditional way for downstream systems to use incremental data, captured in a transactional database, is through Change Data Capture (CDC), with which you can trigger behaviour based on established changes in your database. Think of a deleted account or an updated stock count.
At April’s Data Cloud Summit, Google announced the Spanner change streams in preview, with which one can capture modified data from Spanner databases and easily integrate them with other systems to unlock new value. Change Streams go beyond traditional CDC possibilities. Those streams are quite flexible and configurable so you can track changes in exact tables and columns or in complete databases. You can now replicate changes from Spanner to BigQuery in order to make real-time analysis, activate behaviour from downstream apps with Pub/Sub, and save modifications for compliance purposes in Google Cloud Storage (GCS).
From now on, those options ensure you dispose of the most recent data to optimise your company results. It should also simplify the migration of traditional databases to Cloud Spanner.
Continue reading: Boost the power of your transactional data with Cloud Spanner change streams
Looker receives connection to Connected Sheets
Connected Sheets have existed for a while in BigQuery. The principle is easy enough. One connects what the user knows, a spreadsheet format, with the power of an underlying BI engine, such as BigQuery. That way, you democratise access to information because you do not need SQL experts anymore to make company data accessible on a departmental level. Basic knowledge of the use of Sheets is enough. However, you do work with consistent data that is being collected and managed in a central environment according to the rules of art.
At the Google Data Cloud Summit of April, Connected Sheets was announced for Looker. Connected Sheets for Looker brings modelled data into the familiar spreadsheet interface, so users can work easily and comfortably. Now, we make sure that the integration is more widely available for eligible Looker clients with an Enterprise Workspace licence, based on opt-in.
Looker’s platform offers a unified, semantic modelling layer that works within Looker and through Google Spreadsheets to make joint, ad hoc analysis of cloud data sources possible. It means you can still centrally define metric data that is needed to understand a company, and you can benefit from the scale and freshness of data in the cloud, while still providing access to users to that managed, familiar data. By using the authentication and access mechanisms of Looker, the availability of data does not come at the expense of security.
Continue reading: Analyse Looker-modelled data through Google Sheets
Google is chasing Oracle’s database market …
Legacy systems and databases often get in the way of migration to a digital world. Expensive licences and limiting contracts can strongly restrict the power to modernise and introduce new functionalities. Migrating to open source databases, especially in the cloud, can solve many of those problems and help build modern, scalable and cost-effective applications.
Database migrations are often quite complex, however, and can lead to a need to convert your schedule and code to a new database engine, to migrate your data and switch your applications. Meanwhile, you need to guarantee minimal downtime and disruption of the company in the process.
To support such migrations from on premise to the cloud, Google has been working on the automation of the process for a few years now. They set up the Database Migration Service environment for this purpose. Initially, their focus was on homogeneous migrations, whereby source and purpose databases use the same database engine (PostgreSQL, MySQL or SQL Server). Today, more than eighty five percent of migrations are made and launched in less than an hour using Database Migration Service.
Google announced at The Data Summit in April that, from now on, they would support automated migration from Oracle to PostgreSQL in preview. You can count on a reliable and serverless solution, which means you don’t need to assign resources to the migration task, or predict how many resources it will need. It can transfer your data on a large scale and with low latency from Oracle databases to Cloud SQL for PostgreSQL, which should lead to minimal downtime at the changeover and minimal disruption of both your applications and customers.
Providing this service for Oracle systems is not just an expansion of their services to yet another database environment. It is, however, a clear message that Google is after a top three position in the database market. Look at this diagram from Gartner:

You can see that between 2015 and today, Google has risen to fourth place in terms of market share and now effectively has Oracle in its sights. They also, clearly, feel strong enough to compete in the most demanding market there is in terms of databases. The best proof, arguably, that Google’s offer has matured. Knowing how big the Oracle business is today, it should make for an interesting development in the time to come.
Continue reading: Modernise your Oracle workloads to PostgreSQL with Database Migration Service, now in preview
… but also all other database markets
In recent years, Google has already invested heavily in supporting database migrations, including a series of tools to automate and simplify those processes. They are all separate initiatives that, since April, have been brought together under one umbrella approach: the Database Migration Program. The program is meant for the migration of existing open source and proprietary databases, both on premise and in the cloud, to Google Cloud’s managed database services. The Database Migration Program provides access to assessments, tooling, best practices and resources in the network of specialised database technology partners. The program also offers special incentive funding to compensate for migration costs, enabling customers to migrate their databases to Google Cloud in a quick and cost-effective way.
The uniqueness of this program is the fact that you have access to a one-stop shop for everything related to database migrations. You can break down your migrations into smaller sprints and perform one migration after another, so you can obtain business results more quickly. With the Database Migration Program, you can accelerate your transition from on premise, or other clouds, or self-managed databases to Cloud SQL, Cloud Spanner, Memorystore, Firestore , and Cloud Bigtable.
As the quote above indicates, it helps companies create space in both the time and resources that are needed to realise their digital transformation goals without being plagued by uncertain timelines and high costs.
The Database Migration Program accompanies you from initial assessment and planning phases to the final migration with the expert help of qualified database partners.
Continue reading: Accelerate your move to the cloud with the new Database Migration Program
It has been another Data Cloud Summit edition worth mentioning, if you ask us. Most of all, it tells us that Google is truly aiming for the top position in data processing. Although there is still a lot of work to be done before Gartner can put them at number one, the foundations and the vision are already there. We are looking forward to the future, are you?